
[yummyWiki] awk & sed
꾸준히 띄엄띄엄 들어오는 야미가 돌아왔어여!!
건강상의 이유로 회사를 그만두게 되었거든뇸!! 참 신기하게 사직원을 내고나니 몸이 조금씩 좋아지는 것 있죠...!? 핳하하핳 재미난 몸뚱아리인것 같아욤ㅎㅎㅎ
하지만 아직 이시간에도 퇴근을 못하고 야근을 하다보니 포스팅 하고 싶은 욕구가 마구!! 생겨서 이렇게 오게 되었숨미다 히히
근무중에 포스팅한다구여? 그게 야근이냐구여? 호에!?

ㅋㅋㅋㅋ아 넘웃겨여 감자별에서 고경표의 얄미운 역할... 진짜 최고인것같아욤 ㅋㅋㅋㅋㅋ
오늘의 주제는 바로! 거의 주력이 되어버린 스크립트 중 awk 명령과 sed 명령이예요!! 이야 이 두 개만 다룰줄 알면 그냥 다른 명령어 저리가라 할 정도로!!
먼저 awk 명령을 해보아요! awk 는 Aho, Weinberger, Kernighan 이라는 세 명이 만들어서 awk 란 이름이 되었다고 해요!
이 명령어는 거의 C언어 축소판의 느낌인데, 먼저 사용법을 알려드릴게요!
단독으로 사용할 때엔 awk ' implements ' 로 사용하실 수 있어요.
implements 에 들어가는 것 중 BEGIN{whatelse}, END{whatelse}, /whatelse/, {whatelse} 이렇게 4가지 경우가 있구요, 스크립트 언어의 특징인 함수선언부도 있어요! function name(arg1, arg2) { implements } 이런식으로요!
for 문, if 문도 존재하니.. 거의 C언어가 아닌가욧!? 그래서 제가 아주 애용합니당 ㅎㅎㅎ
최댓값, 최솟값 찾는 스크립트를 예제로 드릴게요!
AWK
example
yummyHit # awk '
> function get_min(num1, num2) {
> if (num1 < num2)
> return num1
> return num2
> }
>
> function get_max(num1, num2) {
> if (num1 > num2)
> return num1
> return num2
> }
>
> function main(num1, num2) {
> result = get_min(num1, num2)
> print "Min =", result
>
> result = get_max(num1, num2)
> print "Max =", result
> }
>
> BEGIN {
> main(10, 20)
> }
> '
문득 소스코드를 넣으려 하다가 보니 이런 좋은것도 있네요!! 신문물은 따라가야 세대차이 극복을.. 쿨럭...
위 코드는 Markdown 이라는 문법만 대-충 그까이꺼 요로케 뚝딱! 하고 만들어주는 것이예요!! 이제 스크린샷 찍어서 할 필요도 없어졌네욤 이런 좋은세상 ㅜㅜ
위 코드와 같이 터미널에서 적으시면 어떻게 동작할까요!? 대충 눈치는 채셨죠!?
review
awk ' 를 통해서 다음에 '(single quote)가 나오기 전까지 코드를 입력하겠다! 하는 것이예욤 ㅎㅎㅎ
그리고 이제 function 을 통해 함수를 선언하는데, function 이 붙는다 뿐 C언어랑 같지않나욤!? 모든자료형을 오케이 해주는것이예욤!! 이렇게나 편리할 수가 ㅜㅜ 야미가 스크립트쟁이 다되었네욤 히히
이렇게 min 과 max 를 구하는 함수, 그리고 main함수(꼭 main이 아니어도 됨니다! C언어와는 달라유! 이건 컴파일언어가 아니잖아욤! calc 라든지 hello 라든지 아무거나로 함수명 쓰셔도 되어욤!)에서 min 과 max 를 가져와 출력해주는 그런 코드예욤!!
그리고 마지막으로 BEGIN 을 통해서 main 함수를 호출하게 되지욤!!
그런데 굳이 스크립트를 사용해서 이렇게 할 필요가 있는가!? 이미 C든 C++이든 언어를 사용하고있는디!? 사실 목적은 저것이 아님니다 ㅎㅎㅎ 데이터 파싱을 위한 awk 사용이죠!!
보통 일반 파일의 주석은 ;(semi-colon)이나 #(comment), //(double slash)를 사용하는데, XML 파일의 경우 주석을 <!-- --> 를 사용하잖아요!? 즉 multi line 이 문제가 되는것이예요!! 물론 소스코드에서 /* */ 도 같은 축에 끼는것이구요!! 솔직히 주석처리 부분은 데이터에 이용가치가 없잖아요!?
이럴 때를 위하여 awk 사용을 빠밤!! 예를 들어 tomcat 의 server.xml 을 예제로 해볼게요!
tomcat origin test file
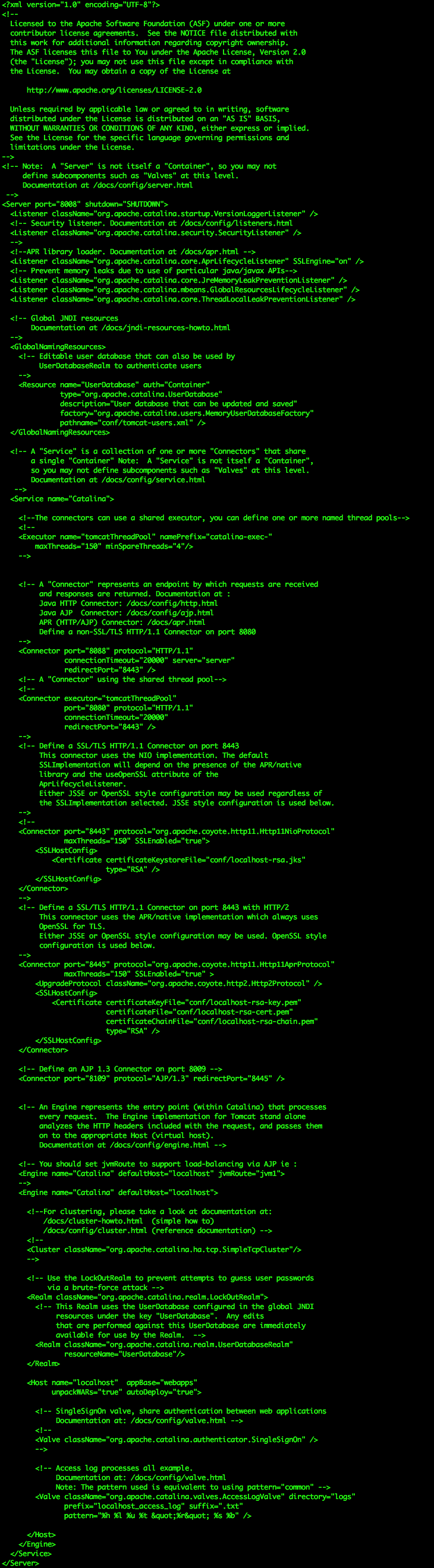
어후.. 길군뇨 ㅜㅜ 실제로 사용되는 설정 값은 얼마 안될텐데 말이예요! 이제 여기서 awk 를 사용하여 주석제거를 해볼까요!?
tomcat parse test file
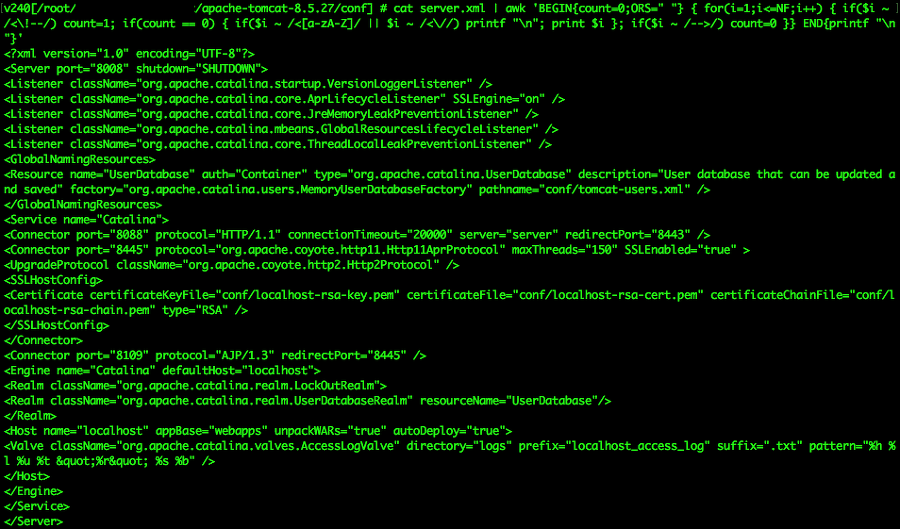
확 줄어들었죠!? server.xml 을 cat 명령을 통해 읽는데, pipeline 을 이용해서 awk 명령으로 한 번 커스텀하는 작업이예요!
여기서 갑자기 BEGIN에 튀어나온 ORS는 무엇인고!?
| 변수 | 내용 |
|---|---|
| FS(Field Separator) | 필드 구분자(Default: White space) |
| RS(Record Separator) | 레코드 구분자(Default: New line) |
| NF(Number of Field) | 현재 필드 번호 |
| NR(Number of Record) | 현재 레코드 번호 |
| OFS(Output Field Separator) | stdout 될 때의 필드 구분자 |
| ORS(Output Record Separator) | stdout 될 때의 레코드 구분자 |
이렇답니다! 즉,
BEGIN{ORS=" "} 이 된다면 기본적으로 New line 으로 stdout 해주는 것을 White space 로 바꿔준다는 의미가 되는것이죠!
그리고 나서 각 필드마다 검사를 하기 위해 for(i=1;i<=NF;i++) 반복문을 이용하구욧!! 여기서 $i 를 통해 기본 필드 구분자인 White space 기준 모든 필드중 <!-- 이 있는지 검사하는것이예욤! <!-- 이 들어가있다면 count=1; 로 지정해줘서 주석이라고 인식하게 되는것이죠!
주석처리의 끝부분인 --> 구문이 나오면 다시 count=0; 으로 복귀!
그럼 주석이 아닌 구문은 count 값이 0인 상태이겠죠!? count 값이 0일 때, Markup Language 의 기본문법인 Tag 라면 printf "\n" 을 통해 개행을 시켜줍니다!
이거 안해주면 한줄로 쫘악~
레코드 구분자를 스페이스로 바꿨기 때문에 읽기 불편해져욤!!
이렇게 해주면 위 사진과 같이 주석제거한 xml 파일을 읽을 수가 있답니다!! 참으로 신기방기하고 써먹기 좋은 명령어가 아닌가욧! 히히
자 그럼 awk 에 대해선 어느정도 느낌이 오시나욤!? 그럼 다음 명령어인 sed 를 살펴보아요! sed 는 딱히 여러 기능은 없지만, 문자열 치환으로 파일을 새로쓸 때 참 좋아요!
SED
vim 편집기에서 :%s 를 통해서 문자열 치환 하시죠!? 이것이 sed 의 기반입니당!! sed 는 stream editor 의 준말이예욤!
sed 를 잘쓴다는 것은 결국 regular expression(regex, 정규표현식)을 잘 알아야해요! 야미도 아직 넘나 어려워하는 정규표현식이네욤 T^T 조금만 공부하면 금방 할 것 같은데 마음이 내키질 않아서..히히
echo "hello" | sed -e 's/hello/yummy/'
이것을 수행하게 되면 예상대로 hello 라는 문자열이 yummy 로 치환된답니다!
echo "yummy" | sed -e 's/m/p/g'
를 수행하면 yuppy 가 되겠져!? 1개 문자를 치환하는 것에는 sed 보다 tr 명령어를 이용함이 더 좋긴 하지만여..ㅎㅎ tr 'm' 'p' 를 하면 모든 m 이라는 문자를 p 로 치환할 수 있거든요! 하지만 tr 의 한계점이라면 바로 정규표현식!
만약 yummy 라는 문자열에서 마지막의 y만 바꾸고 싶다!
echo "yummy" | sed -e 's/y$/p/'
이렇게 해주면 끝문자가 y인 것만 p로 바꿔주는 것이예요! 결국 sed 의 사용법은
sed [option] 's/regex/replace/[flag]'
이렇게 되겠네욤! 오잉? 플래그요? 갑자기 플래그가 왜나왕?
위에서 yummy 를 yuppy 로 바꾼것에서 마지막에 들어간 g가 보이시나욤!? 이것이 플래그랍니당! 만약
echo "yummy" | sed -e 's/m/p/'
를 하게되면 처음 만난 m 만 p 로 치환해주어요! 즉 yupmy 가 된다는 것이죠! 여기에 g 플래그를 넣어주면 all 의 의미가 있어욤(group 이라고 생각하시면 쉽게 외워지실거예욧ㅎㅎㅎ)
사실 sed는 이 외에 사용용도가 엄청나게 많지만.. 거의 치환용도로 많이 쓰이더라구욤 ㅎㅎ 이왕 sed 한 거 유용한 팁 드릴게욥!!
데이터 파싱할 때 주석 제거를 위해 첫 문자 이전 공백 제거 및 공백의 multi line 제거에도 sed를 사용할 수 있어요!
만약 아래와 같이 주석이 걸려있다면!?
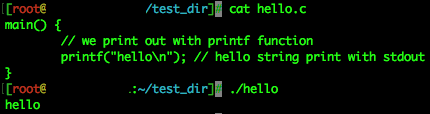
보통 주석 제거할 때 grep -v 를 이용해서 제거하는데, 저렇게 함수 뒤에 주석을 달아놓으면 해당 라인도 제거되어버려서
![]()
이렇게 덩그러니~ 되어버리겠죠!? 우리가 원하는 것은 주석만 있는 라인 제거인데 말이예요!! 그럴 때엔 sed 를 사용해서 공백을 제거해버리는겁니다!!
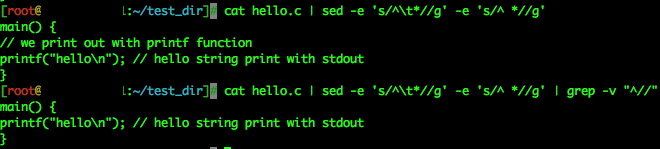
짜란!! 이런 식으로 첫문자가 tab 이거나 white space 인 경우 없애부러! 하는 것이예욤 ㅎㅎ 데이터 파싱에 공백은 필드 구분 외에 쓸데가없어요~ 단 1도!

ㅋㅋㅋㅋ이거 너무 무서워염... 정색하면서 단 1도.. 이러는데.. 잠시 쉬었다 가기위해 웃기위한 짤이니 기분상하지는 마시구욤!!
정규표현식이 사용되었지만, 저도 아직은 정규표현식을 잘 모르니 이렇게 사용할 수 있다라는 것만 알려드리고 오늘은 이만 포스팅을 마칠까해욤!!
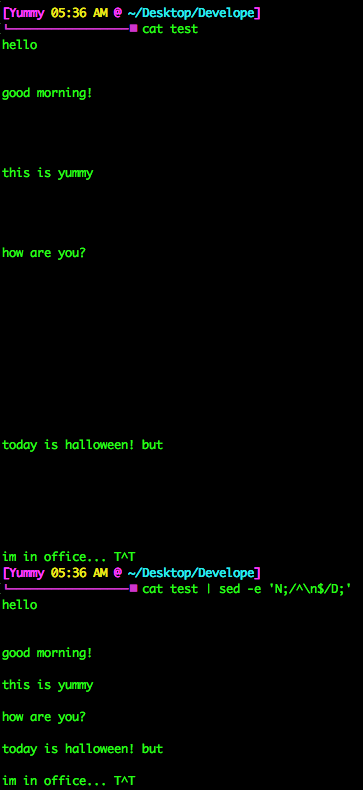
가독성을 위해 사용하기 참 좋은 명령어들 아닌가욧 ㅎㅎㅎ!?
조만간 퇴사 후 재미난 주제로 찾아올게요!! 지금 하고싶은것도 너무 많고.. 포스팅 할 주제도 너무많아서 흥분 고조예욤 히히
그럼 다음 포스팅까지 좋은 날만 가득하세욤!!

회사에서 몰겜하는 초고속 반응속도 회사원의 짤을 오늘의 마지막 짤로 짜란!
Check out the yummyhit’s website for more info on who am i. If you have questions, you can ask them on E-mail.




댓글남기기